powered by
ASTcentric
Motto: Forget the source code but keep the Abstract Syntax Tree (AST)The aim of the ASTcentric project is to develop a framework (in Java) for AST-centric IDEs. There exists a prototype (ASTcentric Study 1). It is a proof of concept that demonstrates some aspects of the AST-centric paradigm. The framework (AST structure classes, plain AST editor, Eclipse plugin) is in an alpha stage.
- From Text-Centric to AST-Centric Programming
- Abstract Syntax Tree and Abstract Syntax Graph
- Implications of AST-Centric Programming
But the linear text represents a non-linear hierarchical structure. Using new-line characters and white spaces helps to visualize this structure. Modern editors for programmers and IDEs support structure visualization with additional helps as e.g. syntax highlighting. Sophisticated IDEs go even further by visualizing compile errors on the fly and helping with code-completion and refactoring.
In this mainstream paradigm of text-centric programming the compiler takes the source code and creates an executable in two major steps:
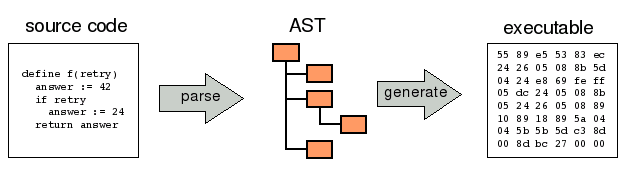
- The sequence of characters is parsed and an Abstract Syntax Tree (AST) is created.
- From the AST the executable code is generated.
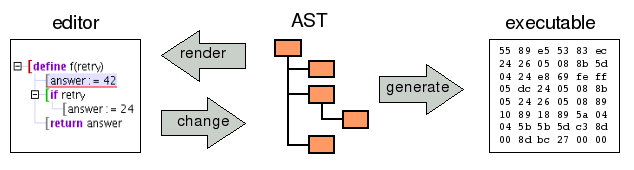
In the paradigm of AST-centric programming the AST becomes the center. It is the master which has to be made persistent. Source code is only one way to feed it. More important will be editors which visualize and manipulate the AST.
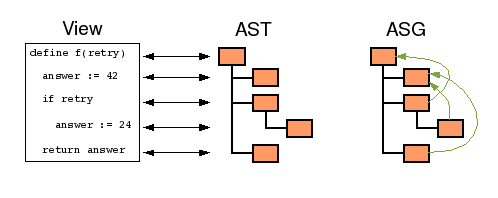
When the AST is mentioned, often not the Abstract Syntax Tree is meant but the Abstract Syntax Graph (ASG). It is the AST plus additional references (pointers) between nodes. For example, a node using a variable refers to the node where the variable is defined. As a consequence a name of a variable appears only once in the ASG.
- The AST is the model that feeds various views/editors. Plain ASCII source code is only one of them.
- Textural and visual views are possible. Usually we will have a mix of both as in the ASTcentric Study 1 Prototype.
- Some views showing not all details.
- Views can be shown simultaneously.
- Views can be customized. Coding style guides are no longer needed.
- Specialized views become possible (e.g. for mathematics).
- Grammatic, EBNF, and Parsers are becoming obsolete. They are only needed to transform legacy code into ASTs.
- Editing means manipulating the AST. Each editing command transforms the AST. In text-centric programming one can add arbitrary text into the source code whether it makes sense or not. In AST-centric programming you can enter only what can be represented in the AST. Code-completion becomes another meaning: Selection of an AST transformation. The set of transformations depend on the context. Even though AST-centric programming is more restrictive it allows sophisticated transformations which are tedious in text-centric programming (e.g. swap left and right operand in a binary expression). Most refactoring methods can be understood as high-level language-aware editing commands. An important sign of quality of an AST-centric IDE is how many AST transformations are available. The main aim of the ASTcentric Study 1 Prototype was just to study this aspect of AST-centric programming.
- The AST is the source. The AST has to be stored and retrieved. The persistent storage can be files or a database. Because an AST is not a linear structure there is no canonical way to serialize it. In Java a natural way would be the built-in binary serialization. XML serialization is another popular choice. For a traditional source versioning system like CVS a textual serialization with newline characters should be preferred.
- Code generation is just another view onto the AST. Various types of generators are conceivable:
- Generator for machine code.
- Generator for byte code.
- Generator of source code of some target language.
- Converter between AST's of different AST-centric IDE's or different languages.
- Interpreter (see e.g. ASTcentric Study 1 Prototype which includes a debugger).
- AST-centric programming makes it easier to extend a language. A programming language is now defined by the types of nodes in an AST and the rules to combined them. Adding a type of node extends the language. Of course this has the consequence to extends all existing views and editors, too. Such extensions could be made possible by a plug-in architecture. An IDE which allows the user to do this with built-in functionality is a language workbench.
(C) 2005-2007 Franz-Josef Elmer. All rights reserved. Last modified: 6/15/2007